Introduction
ETL (Extract, Transform, and Load) data process to copy data from one or more sources into the destination system. Data-warehousing projects combine data from the different source systems or able to read a portion of data from a large set. Data is stored in a flat-file will be converted into Quarriable format at the presentation layer where analytics can be performed.
Meanwhile, AWS glue will be used for transforming data into the requested format.

Extract
Data is placed in the S3 bucket as a flat-file with CSV format. These files or files will get transformed by glue.
The input file to test can be download from below link —
Transform
AWS Glue used to fetch data from flat files and create a Glue table using that file. I am working on a very small set of datasets with “US National Park” information. I have updated some of the data with additional fields that will break in normal transformation.
Input data — This has listed all US National Parks and its information

Yellowstone Park has spanned across 3 states so quotes will be used to consider that field as part of a single-column “state”. The comma (“,”) as a separator will cause issues. State value can be just “‘Idaho” rather than “Idado, Montana. Wyoming”. So we need to transform this data into a meaningful one.

Load
Upon creating a table from a flat-file. AWS Athena will be able to fetch data for analytics purposes or load it into a new environment. I am using “AwsDataCatalog” as an Athena data connector for AWS Glue.
Implementing using Terraform
Terraform software tools can be used to deploy infrastructure as code. We can change infrastructure efficiently and repeatedly with changing input parameters.
Following information needed –
· S3 bucket information and folder name where input data is present. As a best practice, I have added my bucket information into the parameter store rather than adding it into code. Make sure parameter “s3bucket” is created with value <s3://bucketname/>

· Glue Database and table name
· Table Schema matching input parameter
Provider information. I have intentionally added the “access_key” and “secret_key” parameter and hashed it out to ensure no one should add that information in provider information instead create AWS profile using “aws configure” command. My profile name is “ya”. A profile can be different for different application or implementation.

Download source code of Terraform from below location –
https://github.com/yogeshagrawal11/cloud/tree/master/aws/athena/s3_to_athena/
Once source code is downloaded in the same directory as terraforming software. run following command —
aws configure : To configure AWS profile. Make sure appropriate roles are assigned.
terraform init : to initialize terraform
terraform plan : To review plan
terraform apply : To deploy your infrastructure
Run terraforming code to deploy as Infrastructure as code. This code will create two resources, AWS Glue database and AWS Glue Table

Implementing using AWS console
AWS Glue
I am not using the crawler here since this document is the first step in the ETL process. The crawler is needed in case input data is not static. We need to create a schedule to run crawler periodically for new data.
Create the AWS Glue database


Create the AWS Glue table. The location is the S3 input location. Select S3 bucket and folder name where input data is stored. Add Glue table name. Select the appropriate Glue database name.


Select S3 as a type of source and bucket name by clicking the folder image next to the text box
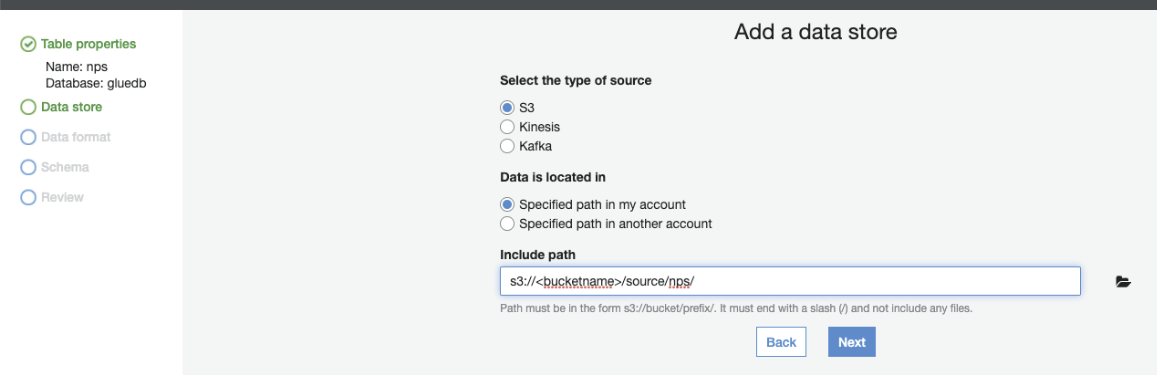
Select classification and Delimiter as per inputs. Avro and Parquet is a new growing data format technique. JSON still widely excepted by many IoT devices worldwide as output technique. Select the appropriate classification and delimiter. I

Add all column

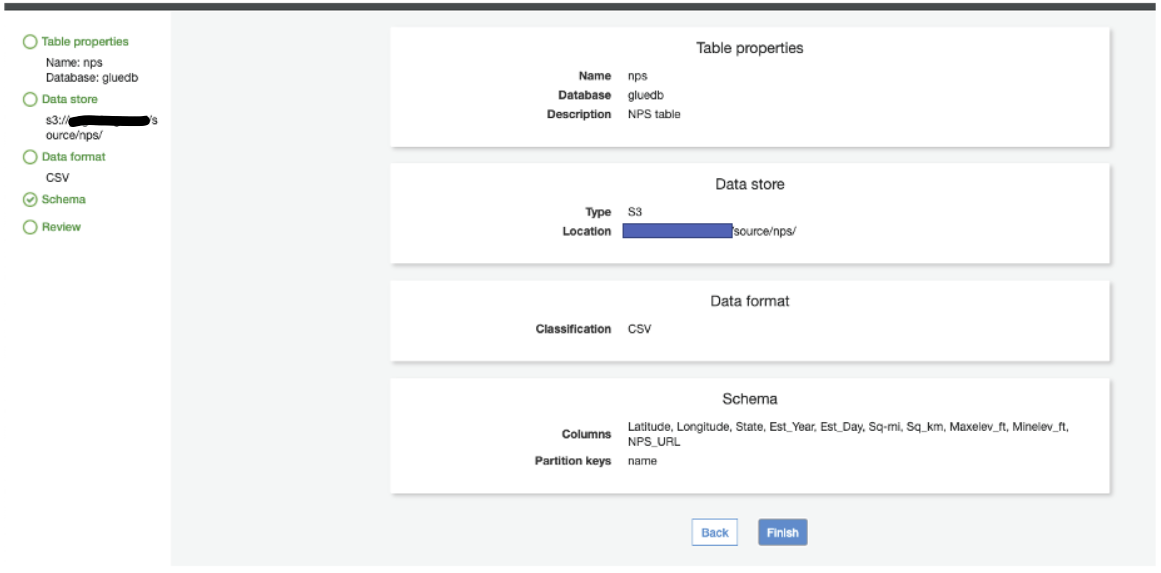

Table properties
Since my data do have a double quote, I have to transform that data from multiple fields into a single field using quote Character. The default “serde serialization” library is also changed to openCSVSerde.
Modify table property Add appropriate Serde Serialization and Serde Pameters as mentioned below. Each parameter will de define how each row is parsed. If quote char found in a field, that field will be a single entity until closing quotes. For ex. in case of “Yellowstone” national park.


Column and Data type can be defined or automatically generated. Defining manually normally does have better results.

Athena Magic
Use data source at “AwsDataCatalog” to connect Athena with AWS Glue.

Enjoy running queries on data.

Most National Park by state.

Athena is a good tool to get data from different connector like AWS Document DB, AWS DynamoDB, Redshift, or even Apache HBase. That will be another story.
Conclusion
Amazon glue is a great tool to perform different types of ETL operations. Use a crawler schedule for running and updating data periodically. AWS makes things movement seamless. New jobs can be scheduled via Scala or Python.
Resources :
https://www.terraform.io/intro/index.html
https://docs.aws.amazon.com/glue/latest/dg/what-is-glue.html